



인공지능 연구를 직접 하고 싶은 의사를 위한 조언 3 – AutoML과 그 외
 0
삼성서울병원 AI연구센터 조백환
0
삼성서울병원 AI연구센터 조백환
조백환 교수님은 Carnegie Mellon University 박사후 연구원, 삼성전자 종합기술원 전문연구원을 거쳐 2017년부터 현재까지 삼성서울병원 AI 연구센터에서 교수로 근무하고 있습니다. 인공지능 연구의 전문가로서 관련 연구를 직접하고 싶은 의사를 위한 조언에 대해서 3회에 걸쳐 연제하고 있으며 그 중 3편을 웹진 5월호에 소개합니다.

Automated Machine Learning (AutoML)
Wikipedia에 AutoML은 다음과 같이 정의되어 있습니다. 즉, AutoML은 기계학습 기술을 실제 문제에 적용하는 과제를 자동화하는 프로세스로써, 기계학습 전 과정에 적용될 수 있습니다.
Automated machine learning (AutoML) is the process of automating the tasks of applying machine learning to real-world problems. AutoML potentially includes every stage from beginning with a raw dataset to building a machine learning model ready for deployment.
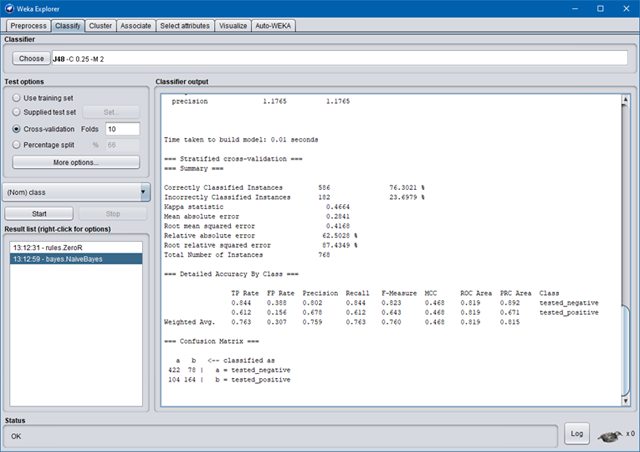
인공지능이나 기계학습 분야의 초심자들도 쉽게 사용할 수 있는 WEKA라는 Java 기반의 무료 데이터 마이닝 및 기계 학습 SW가 있습니다 (아래 그림). 사용자가 쉽게 사용할 수 있도록 Graphic User Interface가 잘 구성되어 있어서, 마우스 컨트롤 만으로 원하는 알고리즘과 hyperparameter를 설정해서 모델을 학습할 수 있는 장점이 있습니다. 하지만, hyperparameter 조합 하나씩 적용하고 결과를 확인한 후 다시 다른 조합을 적용하는 과정을 수작업으로 반복해야 하기 때문에, 실제 연구를 위해서는 오히려 더 많은 시간이 소요되기도 합니다. 이러한 불편한 점을 개선하기 위해 Auto-WEKA라는 툴이 WEKA에 이식하여 사용할 수 있도록 약 10년전에 공개되었습니다. 벌써 10년전에 개발된 SW이므로 현재에 사용하기에는 여러가지 제약점과 불편한점들이 여전히 많이 존재합니다만, 아마도 Auto-WEKA가 일반 사용자들이 사용해 볼 수 있는 AutoML 툴의 가장 최초가 아닐까 싶습니다.
일전에 소개해 드린 바와 같이 최근 IT 대기업들을 중심으로 클라우드 컴퓨팅 서비스가 많이 소개되고 있고, 뿐만 아니라 Google, Microsoft, IBM, Amazon 등의 기업들은 AutoML 기능을 클라우드에서 제공하고 있습니다. 특히 Google Cloud Platform은 AutoML 기능의 일부를 무료로 제공하고 있습니다. 영상, 테이블 (정형) 데이터, 비디오, 텍스트 등 다양한 형태의 데이터에 대해 실행해 볼 수 있습니다. 내가 갖고 있는 데이터를 안내에 따라 클라우드에 업로드 시키고, 내가 원하는 task (영상을 분류하거나, 질병을 예측하는 등)를 지시에 따라 잘 정의해 주면, 결과가 금방 도출되는 것을 볼 수 있습니다.
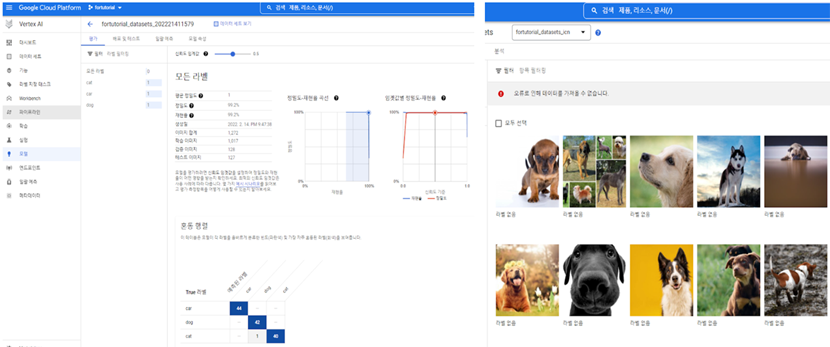
그렇지만, 궁극적인 AutoML 기술은 아직은 가야할 길이 멉니다. 위에서 소개해 드린 Google의 AutoML 기능 무료버전은 실제로 어떤 딥러닝 구조나 기계 학습 알고리즘, Hyperparameter가 어떤 전략을 이용하여 선택되었는지 확인하기 어렵습니다. 따라서, 연구 결과 보고나 논문 작성을 위해서는 결과 해석에 제약점이 있을 수밖에 없습니다. 경제적 측면을 고려해보면, 더 좋은 성능을 내는 모델을 학습하기 위해서는 더 많은 리소스를 투입하도록 옵션을 설정해야 하며, 이는 무료버전에서는 감당할 수 없고 예상보다 훨씬 더 많은 과금이 요구되기도 합니다. 즉, 연구자가 직관에 의해 탐색 범위를 좁혀 가며 학습을 진행하는 것이 훨씬 더 효율적이고 더 좋은 성능을 보이는 모델을 학습할 가능성도 존재합니다. 기술적인 측면에서 보더라도 인간이 직접 전략을 갖고 수행하던 Hyperparameter 최적화를 관련 알고리즘들에 의해 자동으로 수행하는 것이지만, 이러한 AutoML 서비스도 대부분 자체적인 탐색범위를 한정해 두고 있기 때문에 항상 최상의 결과를 보장하지는 못합니다. 따라서, Computing 자원이 충분한 초심자라면 Base-line 성능을 살펴보는 정도로 시도해 보면 좋을 것 같습니다. (물론 AutoML 기능을 활용한 결과를 이용해서 논문을 출판한 경우도 심심치 않게 찾아볼 수 있습니다.)
그 외 몇 가지 팁
기계학습 기법을 활용한 인공지능 모델들은 주로 데이터로부터 학습하여 복잡한 패턴을 찾아내도록 고안되어 있는데, 이러한 이유로 대부분의 기계학습 모델들은 복잡한 비선형 모델들입니다. 따라서, 특히 딥러닝 기술이 적용되는 Neural Network 모델을 포함하여 복잡한 비선형 기계학습 모델들은 학습에 사용된 데이터들을 여러 번 오래 학습시키면 결국 나중에는 거의 100% 정확하게 분류 (혹은 예측)하게 됩니다. 그러므로, 기계학습 모델의 성능을 보고할 때에는 모델을 학습할 때 사용하지 않았던 데이터를 이용하는 것이 일반적입니다.
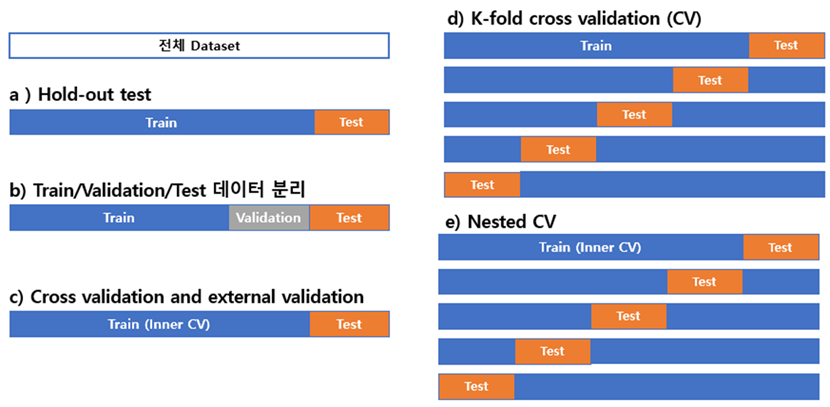
위 그림에서 보다시피 전체 Dataset중 일부를 Test용으로 제외해 두고 나머지 데이터만으로 학습을 진행하는 방식이 Hold-out test입니다. 일반적으로 전체의 70% 이상을 학습데이터로 사용하게 되는데, 학습된 모델을 test 데이터에 적용한 후 그 결과를 보고하게 됩니다. 그러나, 이런 방식의 성능보고는 매우 대량의 데이터 (수 십만 case 이상?)를 이용한 경우가 아니라면 사용하지 않습니다. 우연히 학습데이터와 테스트 데이터가 기가 막히게 잘 분할되어 매우 좋은 성능이 보고될 수 있는 Bias에 대한 우려가 있기 때문입니다. 따라서 조금 더 강건한 (Robust) 결과를 보고하기 위해 이중으로 성능을 검증하는 b)와 같은 방식이나 d) Cross Validation 기법을 많이 사용하여 성능을 보고 합니다. 특히 e)와 같은 방법은 가장 강건한 방식의 검증 방법인데, 전체데이터가 비교적 적고 Computing 자원이 풍부하다면 시도해 볼만한 방식입니다. 또한, 의료 데이터에 대한 검증에 대해서는 학습 데이터를 취득한 기관 외에 다른 기관에서 확보한 데이터로 검증하는 External Validation을 많이 요구하고 있습니다. 따라서 연구를 시작할 때, External Validation을 염두에 두시길 추천합니다.
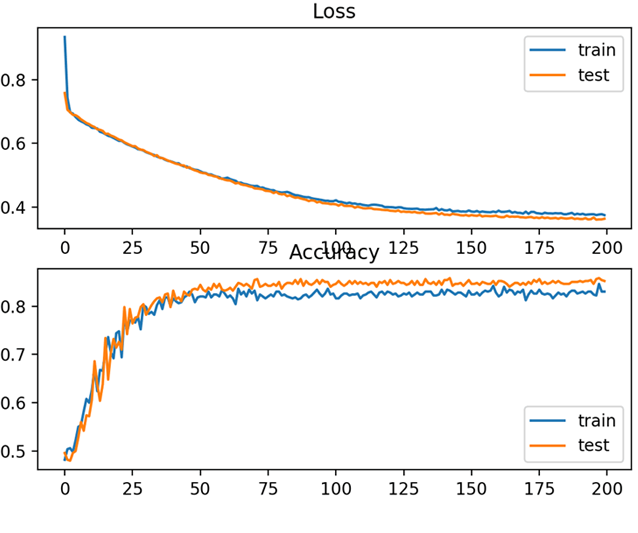
일반적으로 Neural Network을 활용한 딥러닝 연구의 경우 위와 같은 그래프를 그려보면서 확인합니다. X축은 학습 시 반복횟수 이므로 시간 (Time)으로 봐도 무방할 것입니다. 보통은 학습시에 손실 (Loss) 함수를 최소화하는 방식으로 진행하니까 그림처럼 시간에 따라 점점 손실 값이 줄어드는지를 확인하는 것이 필요합니다. 마찬가지로 정확도나 AUC 등의 성능지표가 학습이 진행됨에 따라 지속적으로 상승하다가 어느 지점에서 유지되는 현상이 있는지 확인하는 것이 필요하며, 이러한 그래프가 확인된다면 학습이 일차적으로 성공적으로 수행되었다고 보면 됩니다.
학습을 진행했는데 전혀 원하는 결과가 나오지 않는다면 (예를 들어 accuracy가 말도 안 되게 낮거나 높게 나온 경우) 데이터의 Label을 먼저 확인해 보시면 좋을 것 같습니다. 사용하는 SW 툴에 따라서 0,1,2 형태로 출력 Label을 제한하는 경우도 있으니 원본 데이터에 1과 255로 구분되어 있는 지 확인해 보세요. 또한 Label 즉 정답 값을 실수로 입력데이터에 넣어버리는 실수도 하곤 합니다. 데이터를 정규화 (Normalize)하지 않았는지도 확인해 보아야 합니다. Neural Network의 경우에 정규화하지 않은 데이터를 그대로 학습하면 원하는 결과를 얻지 못하는 경우가 많습니다. 이 후에 다양한 Data Augmentation, Feature Selection 방법이나 Ensemble 방법들을 찾아서 적용해 보시면 조금이나마 성능 향상을 확인해 볼 수 있을 것입니다.
마치며
소개해 드린 내용 외에도 더 다양한 궁금한 점이 많으실 것입니다. 세상에 수많은 질병들처럼 AI 연구에 있어서도 마주치는 문제들도 다양하기 때문에 한정된 지면에서 소개해 드리기가 어렵다는 점이 안타깝습니다.
아마 실제 연구를 해보면 “인공지능은 만병통치약이 아니다”라는 것을 많이 느끼실 겁니다. 학습 자체는 컴퓨터가 하겠지만, 연구자가 세심하게 신경을 쏟아야 최적의 모델을 찾을 수 있음에는 틀림이 없습니다. 그래서 어떤 이는 인공지능 연구 과정을 “모래사장에서 바늘 찾기”에 비유하기도 하고, 또 다른 이는 “예술”에 비유하기도 합니다. 힘들지만 성취감이 있는 즐거운 “예술” 활동에 조금이나마 도움이 됐으면 하는 마음으로 졸필을 마칩니다.