



인공지능을 이용한 중이질환의 진단
 0
서울아산병원 의공학연구소 권지훈
0
서울아산병원 의공학연구소 권지훈
중이염은 모든 연령대에서 흔히 발생하는 질환으로, 증상의 다양성과 복잡성 때문에 정확한 진단이 어렵다. 특히 이통(ear pain), 난청(hearing loss), 현훈(vertigo), 안면마비(facial palsy) 등 다양한 이비인후과적 증상들은 중이의 구조적 이상과 밀접한 관련이 있다. 진단의 첫걸음은 고막(tympanic membrane, TM)과 중이의 시각적 평가이며, 이를 위해 내시경(otoscope 또는 otoendoscope)이 사용된다. 그러나 이러한 영상 기반의 진단은 숙련된 전문가의 경험에 의존하기 때문에 진단 정확도가 고르게 유지되기 어렵다. 실제 임상에서는 숙련된 이비인후과 전문의 간에도 고막 병변에 대한 진단 일치도가 50~73% 사이로 보고된다. 이에 따라, 고막과 외이도의 영상을 기반으로 한 자동화된 인공지능(AI) 진단 보조 시스템의 필요성이 대두되고 있다.
서울아산병원의 연구팀은 4만 장 이상의 중이 내시경 영상을 리뷰하고 구축한 대규모 데이터베이스를 바탕으로 고막 질환을 자동 분류하는 딥러닝 모델을 개발하였다. 2018년부터 2020년까지 수집된 총 6,630장의 영상은, 환자 식별 정보를 제거한 후 숙련된 전문의에 의해 독립적으로 주석 작업이 이루어졌고 진단이 일치한 영상만을 최종 데이터셋에 포함하였다. 특징적인 점은 동시에 발생할 수 있는 질환과 동시에 발생할 수 없는 질환으로 분류하여 다층적인 레이블을 부가하였다는 점이다. 중복이 불가능한 주요 진단군으로서 중이 삼출성 중이염(OME, 1,630장), 만성 중이염(COM, 1,534장), 삼출성 중이염과 만성 중이염이 없음(None, 3,466장)으로 분류되었다. 이 외에도 상고막 각화낭(attic cholesteatoma), 고막염(myringitis), 이도 진균증(otomycosis), 통기관 삽입 여부(ventilating tube) 등의 부가 병변에 대해서도 각각 이진 레이블이 부여되었다. 이 과정에서 일부 영상은 2개 이상의 병변이 함께 나타났고, 이러한 복합병변 인식은 모델의 학습 과정에 난이도를 더했다. 이를 해결하기 위해 복합 병변의 특성을 충분히 학습할 수 있도록 데이터 증강 기법을 적용하고 Efficientnet-B4 기반의 다중 레이블 학습 구조를 사용하였다. 이러한 접근은 모델의 일반화 성능을 높이는 데 기여하였다.
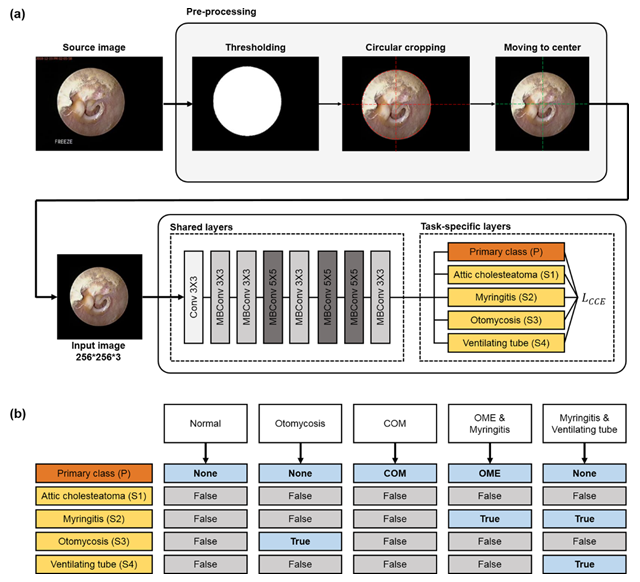
또한 만성 중이염의 경우, 고막 천공 여부만 분류하는 것으로는 실제 임상에서 중요한 천공(perforation)의 크기와 위치 정보를 파악할 수 없다. 이를 보완하기 위해, 영상 내 고막 전체 영역과 만성 중이염에서 발생하는 고막 천공을 분할(segmentation)하는 모델도 별도로 개발하였다. 분할된 결과를 바탕으로 고막 전체 면적 대비 천공 부위의 상대적 면적을 정량적으로 산출할 수 있으며, 이는 병변의 정도를 객관적으로 평가하고 치료 경과를 모니터링하는 지표로 활용될 수 있다. 이러한 정량지표는 전문의 간 평가 편차를 줄이고, 경과 관찰 및 치료 효과 평가에도 도움이 된다.
딥러닝 모델의 또 다른 핵심은 진단 결과에 대한 신뢰도를 평가하는 것이다. 사람도 진단에 있어 확신이 없는 경우가 있듯, 인공지능도 마찬가지로 ‘불확실성’을 가진 예측을 내놓는다. 단순히 예측 확률값만으로 진단의 신뢰도를 판단하는 것은 임상에서 충분치 않으며, 예측 결과의 신뢰도 또는 불확실성을 수치화하는 것이 중요하다. 딥러닝의 불확실성은 크게 데이터 자체의 노이즈나 모호함에서 비롯되는 내재적 불확실성(Aleatoric uncertainty)과 모델의 정보 부족에서 발생하는 지식적 불확실성(Epistemic uncertainty)으로 나눌 수 있다. 내재적 불확실성은 수집 데이터의 품질과 직접적으로 관련되며, 지식적 불확실성은 모델이 학습 데이터로 충분히 학습되지 않은 영역에서 주로 나타난다. 이를 정량적으로 추정하기 위해 예측 확률의 교정(calibration), 베이지안 신경망(Bayesian Neural Networks), 몬테카를로 드롭아웃(Monte Carlo Dropout) 등의 기법이 사용된다.
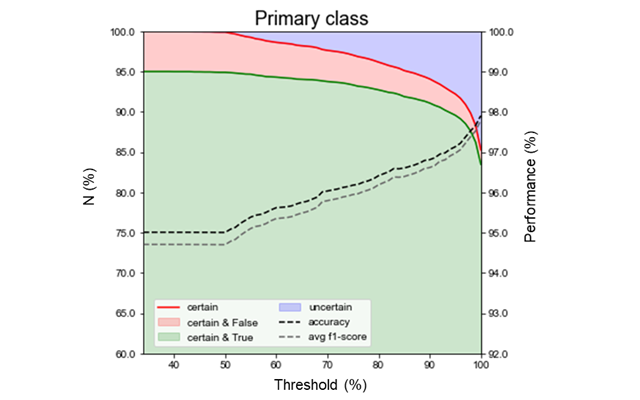
네트워크에 랜덤한 요소를 부가하고 반복적으로 예측하였을 때의 일치도를 기준으로 불확실성을 정량화하는 방법을 개발하였다. 예를 들어, 100번을 반복 예측하였을 때 90번 이상 일치하는 케이스는 진단 정확도가 97퍼센트 였다. 랜덤한 요소 없이 딥러닝 예측을 했을 때에 비해 정확도가 2퍼센트 향상되는 장점이 있었다. 이러한 불확실성 정보는 실제 임상에서 모델의 진단을 그대로 따를지, 또는 재검사를 권유할지를 판단하는 데 중요한 객관적 지표로 기능할 수 있다. 불확실성이 수치로 제공되면 의료진은 신뢰도가 낮은 경우 재확인이나 보완적 진단을 고려할 수 있다. 하지만 인간의 직관적인 판단과 인공지능의 수리적 판단은 본질적으로 차이가 있으므로, 이를 효과적으로 통합하는 하이브리드 진단 보조 시스템의 개발이 앞으로의 연구과제가 될 것이다.
한편, 인공지능 학습에 필수적인 고품질 의료 영상 데이터를 확보하는 데에는 여러 제약이 따른다. 개인의료정보 보호에 대한 규제와 윤리적 문제로 인해 실질적인 데이터 수집이 제한적이며, 전문가에 의한 정밀한 주석 작업에는 상당한 시간과 비용이 필요하다. 이를 보완하기 위해, 행정안전부의 국가 데이터 포털 등의 공공기관에서 제공하는 의료 영상 데이터셋이나 공개된 고막 영상 데이터(예: OME 공개 데이터셋 등)의 적극적인 활용이 필요하다. 서로 다른 조건과 환경에서 개발된 모델의 객관적인 평가 측면에서도 활용도가 높다고 하겠다.
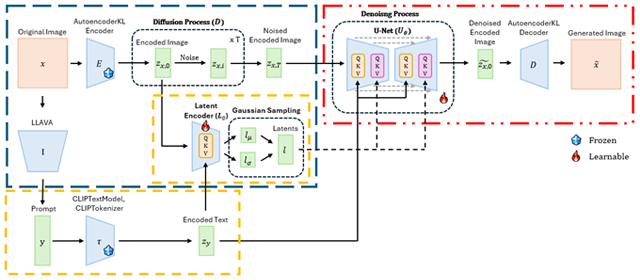
또한, 데이터의 양과 다양성을 확보하기 위해 최근 확산 모델(Diffusion model) 등을 기반으로 하는 인공지능 이미지 생성 기술이 주목받고 있다. 생성형 인공지능 활용으로 실제 환자 정보를 포함하지 않으면서도 학습에 유의미한 고품질의 고막 이미지를 대량 생성할 수 있어, 개인정보 보안과 성능 향상이라는 두 마리 토끼를 잡을 수 있다. 생성형 인공지능 분야에서 OpenAI와 Google 등의 기업들이 꾸준하게 여러 모델을 발표하고 있지만 의료 영상은 해부학적 구조와 전문 용어 등 특수성이 높아 개별화된 모델 개발이 필수적이다. 생성된 이미지는 실제 의료영상과 구별하기 어려울 뿐 아니라(유효성), 환자마다 다른 특성을 반영할 수 있어야(다양성) 모델 개발 및 검증에 활용할 수 있다. 이와 같은 요구를 반영하여 서울아산병원 연구팀에서는 생성 모델의 잠재 공간(latent space)을 세밀하게 조정함으로써 다양하면서도 안정성 있는 이미지 생성기술을 개발하였다. 이를 이용하면 많은 이미지를 수집하고 긴 시간동안 레이블을 부가하지 않더라도 고품질의 인공지능 기술을 개발할 기회를 얻을 수 있다. 개인정보로부터 자유로운 생성 이미지는 교육과 진단 보조 시스템의 발전에 큰 기여를 할 것으로 기대된다.
결론적으로, 인공지능은 중이질환 진단의 정확성과 효율성을 크게 향상시킬 수 있는 잠재력을 지닌 기술이다. 특히 외래 진료 현장에서 수십 명의 환자를 짧은 시간 내에 평가해야 하는 현실에서, AI 기반의 자동 진단 보조 시스템은 의료진의 부담을 줄이고 오진율을 감소시키는 데 핵심적인 역할을 할 수 있다. 다만 인공지능의 임상 적용에는 기술적, 윤리적, 법적 고려사항이 동반되므로, 다양한 이해관계자 간의 협력을 통한 지속적인 연구와 제도적 정비가 필요하다. 인공지능이 단순한 도구를 넘어 의료의 동반자로 자리매김하는 날을 하루빨리 오기를 기대해본다.