



인공지능 연구를 직접 하고 싶은 의사를 위한 조언 1
 0
삼성서울병원 AI연구센터 조백환
0
삼성서울병원 AI연구센터 조백환
조백환 교수님은 Carnegie Mellon University 박사후 연구원, 삼성전자 종합기술원 전문연구원을 거쳐 2017년부터 현재까지 삼성서울병원 AI 연구센터에서 교수로 근무하고 있습니다. 인공지능 연구의 전문가로서 관련 연구를 직접하고 싶은 의사를 위한 조언에 대해서 3회에 걸친 연제를 할 예정으로 그 중 1편을 웹진 3월호에 소개합니다.

스마트폰, 인공지능 스피커, 자율주행 보조기능이 장착된 자동차 등 우리 일상생활에 이미 깊이 적용되고 있는 인공지능 기술은 금융/투자, 교육/취업, 환경/에너지 분야를 넘어, 심지어 예술/컨텐츠 영역에도 그 적용범위를 넓혀가고 있습니다. 이제는 오히려 인공지능이 적용되지 않는 분야를 찾아보는 것이 어려울 정도라고 해도 과언이 아닐 것입니다. 특히 딥러닝 (Deep Learning) 기술이 일반 학계와 산업계에 소개되고 적용되기 시작한 2012년경 이후, 인공지능 기술은 의료 분야에서도 연구단계 뿐만 아니라 인공지능 의료기기, 디지털 치료기기 (Digital Therapeutics), 전자약 (Electroceutical 혹은 Bioelectronic medicine) 등 실용화 및 상용화에도 매우 깊숙이 관여하고 있습니다. 이러한 상황에서 의사 선생님들께서도 연구 논문 작성을 위해, 창업 아이디어를 구현하기 위해, 혹은 순전히 호기심에 이끌려 ‘직접 인공지능 연구를 해볼 수 없을까?’ 고민하시는 분들이 점점 더 많아지고 있을 것입니다. 최근에는 많은 무료 개발 SW와 공유 코드, 관련 서적 및 동영상 강좌 등을 쉽게 찾아볼 수 있어서, 초심자도 조금만 노력하면 왠만한 결과를 도출할 수 있을 정도입니다. 그래서 의사이자 인공지능 연구를 시작해 보고자 하는 분들께 현실적인 팁을 드려보고자 합니다.
연구 목적과 데이터 현황 파악이 우선
그냥 무작정 취미삼아 시작하는 경우가 아니라면, 인공지능을 활용하려는 연구 목적이 있을 것이고 수집 가능한 데이터가 있을 것입니다. 무엇보다 명확한 연구 목적을 먼저 파악하는 것이 중요합니다. 질병의 진단이 목적인지, 질병이나 병변의 정량화 (size, severity 등)가 목적인지, 질병의 발병이나 예후 예측이 목적인지 혹은 특정 질병의 Subtype 도출이 목적인지가 명확해야 합니다. 그 이유는 정확한 목적에 따라 적용해야 하는 인공지능 기법이 달라질 수 있기 때문입니다. 아래 그림에서 볼 수 있는 바와 같이 연구 목적과 보유 데이터의 상황에 따라 가장 적절한 기계 학습 방법(알고리즘)을 선택해야 합니다.
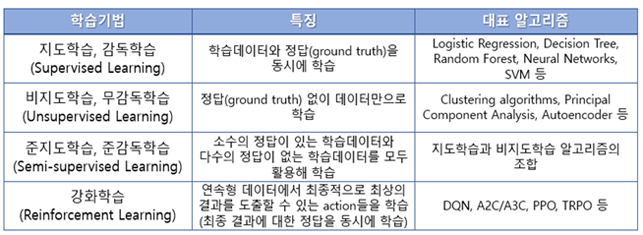
예를 들어 후두암 환자가 수술 후 암이 1년내에 재발할 지 그렇지 않을지 분류하는 연구를 수행하고자 한다면, Supervised learning 기법 중 적절한 알고리즘들을 선택해서 성능을 비교해 보는 것이 필요할 것입니다.
또 다른 예로, 뇌전증 환자의 뇌파 데이터를 확보하고 있지만 대부분 발작이 관측되지 않은 정상상태의 데이터이고, 아주 적은 양의 데이터 구간만이 발작 상태의 데이터일 때는 일반적인 Supervised learning 기법으로는 효과적인 결과를 기대하기 어렵습니다. 특정 Class(양성/음성 등)의 데이터 개수가 다른 Class의 데이터 개수보다 월등히 (수십 배 이상) 많을 때, 이 경우를 흔히 데이터의 불균형 (Imbalanced data) 문제라고 합니다. 이런 상황은 대다수를 차지하는 (Majority) Class의 데이터를 주로 학습하기 때문에, 적은 양이 존재하는 (Minority) Class의 데이터는 무시하게 되는 경향이 발생하게 됩니다. 특히 이 Minority class가 Target 질환이고 Majority class가 정상상태(Normal)라면, 일반적인 Supervised learning 기법으로 학습한 모델은 Majority class의 데이터를 주로 학습했기 때문에 어떤 입력 데이터에 대해서도 거의 항상 Normal이라는 결과를 Output으로 도출할 확률이 매우 높습니다. 이런 경우에 Unsupervised learning 기법이나 Semi-supervised learning 기법을 고려해 볼 수 있을 것입니다.
따라서, 기본적으로 인공지능, 기계학습, 딥러닝 등 각각에 대한 기본적인 개념과 함께 어떤 상황에서 어떤 종류의 기법을 적용해야 할지에 대한 이론은 미리 어느 정도는 공부해 두시는 것이 좋습니다.
데이터는 多多益善, 그러나…
“인공지능을 개발/연구하려면 데이터가 얼마나 필요할까?”라는 질문을 꽤 많은 분들께서 마음속에 갖고 있을 겁니다. 좋은 성능을 낼 수 있는 인공지능 모델을 학습시키려면 당연히 많은 양의 데이터가 필요합니다. 아래의 그래프를 보면 학습 데이터의 양이 많으면 많을수록 평균적으로 그 성능이 높아지는 것을 볼 수 있습니다. 사실 더 주목해서 봐야할 부분은 평균 성능 보다는 성능의 편차입니다. 학습데이터의 양이 적으면 평균적으로 성능이 낮기도 하지만 그 편차가 매우 커서 Robustness나 Reliability가 부족할 수 있습니다. 즉, 학습데이터나 1차 검증을 수행했던 데이터에는 성능이 좋게 보일 수 있지만, 또 다른 검증 데이터에는 전혀 다른 결과가 나올 수 있다는 것을 의미합니다.

통계학적으로는 유병율, Primary endpoint의 값, 검정력 등을 고려하여 필요한 표본의 수를 산정하는 일종의 공식이 있고, 이를 자동으로 계산해주는 소프트웨어도 있지만, 인공지능이나 기계학습의 경우는 이러한 필요 학습데이터 산정 공식(?)이 없기 때문에, 때때로 통계학적 방법을 차용하는 경우가 있기는 합니다. 그러나, 아직까지는 Peer review를 받는 학술지에서도 유병율 등을 고려한 필요 데이터 수를 충분히 학습에 활용했는지 여부를 논문의 Accept/Reject를 결정짓는 필수조건으로 따지는 곳은 많지 않은 것으로 보입니다. 다만, 연구 결과를 논문으로 출판하기 위해서는 내가 이 정도의 학습데이터만을 활용할 수밖에 없었던 이유와 그 한계점에 대해서는 분명하게 언급하는 것이 필요합니다.
학습데이터 수가 많을수록 좋다는 것을 알지만 현실적으로 만족할 만큼 많은 데이터를 확보하는 것은 매우 힘듭니다. 특히나 이제 막 연구를 시작해 보려는 분이라면 그 상황이 더욱 어려울 것입니다. 데이터를 학습에 사용하려면 일단 보유하고 있는 데이터를 잘 정제해야 하고, 의료영상과 관련되어 있다면 상황에 따라서 Annotation을 위한 수작업이 필요할 겁니다. 이러한 작업들을 모두 수행한 후 비로소 학습에 사용할 수 있는 데이터 수를 살펴보면 매우 실망할 만큼 적을 수도 있습니다. 하지만 포기하기엔 이릅니다. 때에 따라서는 수십 케이스 정도의 데이터 만으로도 상당히 신뢰할 만한 모델을 학습할 수도 있기 때문입니다. 연구의뢰를 받고 첫 연구미팅을 할 때, 인공지능 모델이 어느 정도의 성능을 낼 수 있을 지에 대해서 대략적으로 미리 가늠해 보는 저 나름의 기준은 다음과 같습니다.
- 데이터가 얼마나 정형화(표준화) 되어 있는가? 영상이나 생체신호 등 비정형 데이터도 간단한 방법으로 Normalize할 수 있는가? 특히 데이터를 수집할 때 활용했던 기기 등 환경 변화에 따라 데이터의 질(영상의 화질, 생체신호의 잡음 정도 등)에 차이가 큰가?
- 전문가는 동일한 환경에서 그 문제를 얼마나 잘 해결하는가? 비전문가가 간단한 교육을 받는다면 얼마나 잘 해결할 것 같은가?
- 보유하고 있는 데이터가 모집단을 잘 대표할 수 있는가?
- 비슷한 연구를 수행했던 이전 연구사례 (인공지능 방법 혹은 통계학적 방법)에서는 어느 정도 성능을 보였는가?
이러한 기준을 통해 어느 정도 성능을 예측해 본 후, 보유하고 있는 데이터로 최대한 학습을 통해 그 성능 한계치를 확인해 봅니다. 미리 예상해 보았던 성능과 크게 차이가 난다면 제일 마지막으로 데이터 추가 확보에 대한 고민을 하게 됩니다. 그렇지만, 데이터 추가 확보는 정말 최후의 옵션입니다. 저 같은 인공지능 연구자도 주어진 환경에서 최고의 모델을 확보할 수 있도록 최대한 노력을 하고 있으니, 데이터에 대한 불만이나 고민을 하기 전에 먼저 주어진 환경에서 최대한 시도해 보는 것이 중요할 것 같습니다. 임상경험이 늘어남에 따라 Outcome에도 좋은 영향이 있는 것과 마찬가지로, 인공지능 연구 경험도 계속 부딪혀봐야 좋은 결과를 손에 쥘 확률이 높아질 수 있습니다.
내 PC로 인공지능 연구를 할 수 있나? – 개발환경 (H/W)
연구를 시작하려고 데이터를 준비하고 보니 가장 먼저 고민되는 것이 위 질문일 겁니다. 사실 요즘 구매할 수 있는 왠만한 데스크탑PC나 노트PC들도 예전에 비하면 연산성능이 많이 개선되었습니다만, 인공지능 연구를 위해서는 전용 연산 장치가 필요할 수 있습니다. 특히 데이터 사이즈가 큰 영상을 다루고 딥러닝 알고리즘을 이용한다면, 일반 PC로는 몇 주를 학습시켜도 원하는 결과를 얻지 못할 수 있습니다. 이 때 필요한 것이 Graphics Processing Unit (GPU) 입니다. GPU가 부착되어 있는 그래픽 카드는 원래 고해상도 그래픽을 요구하는 게임이나 VR/AR 애플리케이션에서 사용자와 상호작용하여 멋진 영상을 실시간으로 보여주기 위해 만들어진 장치입니다. 흔히 들어 보았을 Central Processing Unit (CPU)은 컴퓨터가 동작하는데 필요한 여러 가지 명령을 처리할 수 있는 멀티 플레이어인데 반해, GPU는 그래픽/영상을 처리하는 데에만 특화된 장치이고 특히나 곱셈과 덧셈을 동시에 수백/수천 번을 수행할 수 있도록 고안되었습니다. (당연히, 비싼 그래픽 카드일수록 한꺼번에 많은 연산을 수행할 수 있습니다.) 일반적으로 인공지능 모델을 학습할 때 곱셈과 덧셈을 엄청나게 반복 수행하게 되는데, 이 때 CPU보다는 GPU가 더 빠른 연산을 수행할 수 있으므로, 이 GPU가 인공지능 연구/개발에 많이 활용됩니다. 실리콘밸리에 위치한 그래픽 카드를 제조하는 유명한 회사인 NVIDIA社는 매년 봄마다 자체 컨퍼런스를 열고, 가죽점퍼를 입은 CEO가 기조연설을 통해 신제품을 홍보합니다. 10년 전엔 신제품이 실사에 가까운 아름답고 현란한 영상을 실시간으로 제공할 수 있는지를 설명하는데 초점을 맞춰 기조연설 1시간의 대부분을 할애했다면, 최근에는 인공지능, 딥러닝 알고리즘을 학습하는데 얼마나 빨리 결과를 만들어 내는지, 딥러닝 학습에 어떤 편리한 특장점을 추가했는지를 설명하는데 대부분의 시간을 쏟고 있습니다. 컨퍼런스 참가자들도 예전엔 게임 개발자들이나 컴퓨터 게임 Geek 들이 주를 이뤘다면, 요즈음엔 인공지능 개발자들이나 관계자들이 많이 유입되어 서로 정보도 공유하고 있습니다. 참고로 Google社에서도 GPU에 대적하기 위해 (NVIDIA社가 GPU라는 이름을 최초로 사용함) Tensor Processing Unit (TPU)이라는 장치를 개발해서 공개했습니다. 그런데 TPU는 대부분 Google Cloud Platform이라는 자체 클라우드 시스템에 적용되어 있어서 클라우드 서비스를 통해서 이용할 수 있고, 일반 소비자가 직접 구매할 수 있는 TPU는 매우 제한적입니다.
다시 본론으로 돌아와서, 내 PC로 인공지능 연구를 할 수 있는지 확인해 보려면 위에 언급한 GPU가 부착되어 있는지를 먼저 확인해 보면 좋습니다. 일반적으로 위에 언급한 NVIDIA社의 그래픽카드를 많이 사용하고 있으니 해당 카드가 부착된 데스크탑 PC나 노트 PC가 좋을 것 같습니다. 물론 GPU가 부착된 그래픽카드가 없더라도 인공지능 연구를 할 수 있긴 하지만, 데이터 개수나 Dimension (영상의 크기 혹은 입력 Variable의 개수 등)이 조금만 커져도 연산속도에 답답함을 느낄 수 있습니다. 그런데 문제는 2022년 상반기 현재에도 전세계적으로 반도체 수급 부족 현상이 지속되고 있고, 그래픽 카드도 예외가 아니어서 가격이 점점 상승하고 있습니다. 저도 호기심으로 최근에 조립 PC 견적을 받아보았습니다. 처음 연구하고자 하는 일반 소비자가 사용하기에 부족함이 없는 RTX 3060 그래픽 카드를 추가하고 11세대 인텔 I7 CPU와 32GB 메모리, 512GB SSD와 4TB HDD 등을 장착한 데스크탑 PC로 구성했더니 약 300만원 정도의 견적이 나왔습니다. 아마 사양을 약간씩 조정하면 조금 더 저렴하게 PC를 구성할 수도 있을 것 같습니다.
PC를 새로 구매하고 싶지 않다면, GPU (혹은 TPU)를 활용한 딥러닝用 클라우드 서비스를 이용할 수도 있습니다. 앞서 말씀드린 구글 클라우드 플랫폼, 아마존 AWS, 마이크로소프트 Azure 클라우드 서비스 등의 글로벌 회사들이 해당 서비스를 지원하고 있고, 국내에도 네이버 클라우드 플랫폼, KT 클라우드 등을 활용해서 연구를 시도해 볼 수 있습니다. 여러 클라우드 서비스의 요금과 사양 등을 비교해보고 가장 적합한 플랫폼의 활용을 고려해 볼 수 있습니다. 하지만, 기계학습, 특히 Neural network을 활용한 딥러닝 모델을 개발하기 위해서는 Try and error를 반복하면서 가장 최적의 모델을 찾아가야 합니다. 때문에, 사용량에 따라 과금을 부과하는 상용 클라우드 플랫폼의 가격은 장기적으로 보았을 때 결코 저렴하지 않다는 것을 염두에 두셔야 할 것입니다. 소규모의 데이터를 활용한 Pilot study라면 클라우드 플랫폼을 고려해 볼 수 있겠습니다. 하지만, 특히 데이터 크기가 조금 커지고 좀 더 복잡한 모델을 학습한다면, 조금 무리해서라도 전용 PC나 워크스테이션을 도입하시길 추천합니다. 물론, 향후에 반도체 수급이 개선되고, 초저전력 컴퓨팅 리소스들이 개발되고, 이에 따라 클라우드 컴퓨팅을 제공하는 회사들이 지금 보다 요금을 훨씬 저렴하게 책정하게 된다면 상황이 달라질 수는 있겠지만, 그 모든 것들이 언제쯤 가능할지 저도 궁금합니다.
다음 편에는 연구를 수행하면서 겪을 수 있는 실질적인 상황에 대해 소개해 드리고, 어떻게 대처해야 할지에 대해 간략히 소개해 드리도록 하겠습니다.