

- 개원가에서 호흡기 전담 클리닉과 재택치료 업무 현황
- 코로나 감염 후 후각 저하
- 외래 술기 완전 정복 고막 환기관 삽입술!
- 어지럼증의 진단, 최신 guideline들을 알려드립니다.
- 인공지능 연구를 직접 하고 싶은 의사를 위한 조언 2 – 실질적인 문제들에 대한 조언
- 좋은 데이터 구축을 위하여 - 연구 문제 정의의 중요성
- 코로나 투병기
- 취미로 배우는 스피드 스케이팅
- 공지사항
- 보험관련 소식
- 2022년 춘계 전공의 연수강좌
- 제96차 대한이비인후과학회 학술대회/ 2022 춘계 대한이비인후과의사회 학술대회
- 대한이비인후과학회 신입전공의 워크샵
- 대한이비인후과학회 제6회 미래포럼


인공지능 연구를 직접 하고 싶은 의사를 위한 조언 2 – 실질적인 문제들에 대한 조언
 0
삼성서울병원 AI연구센터 조백환
0
삼성서울병원 AI연구센터 조백환
조백환 교수님은 Carnegie Mellon University 박사후 연구원, 삼성전자 종합기술원 전문연구원을 거쳐 2017년부터 현재까지 삼성서울병원 AI 연구센터에서 교수로 근무하고 있습니다. 인공지능 연구의 전문가로서 관련 연구를 직접하고 싶은 의사를 위한 조언에 대해서 3회에 걸쳐 연제하고 있으며 그 중 2편을 웹진 4월호에 소개합니다.

프로그래밍은 어떤 걸로? – 개발환경 (S/W)
요즈음 딥러닝 개발을 위해 가장 많이 사용하는 프레임워크는 PyTorch, TensorFlow, Keras 등이 있습니다. 최근 AI 관련 학회들에 발표된 논문들을 보면 가장 많이 사용한 프레임워크는 PyTorch와 TensorFlow이고, Keras는 비교적 초심자들이 접근해서 활용하기 쉽습니다. 아마 처음 딥러닝을 시도하시는 분들은 Keras로 시작하는 것이 성취감을 빨리 맛보기에 좋을 것 같습니다. 하지만 뭔가 나만의 알고리즘이나 네트워크 구조를 위해 코드를 수정하고 싶은 욕구가 생길 때에는 PyTorch나 TensorFlow 등 Low-level에서 코드 수정이 가능한 프레임워크로 옮겨가야 합니다. 아래 표에 간략하게 이 프레임워크들을 비교해 두었습니다.
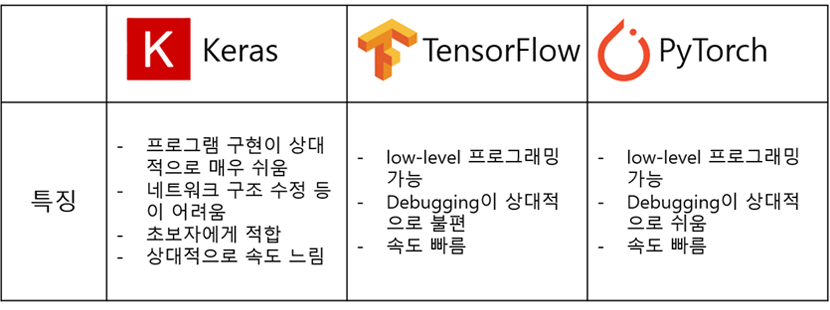
그런데 위 프레임워크들은 공통적으로 Python프로그래밍 환경에서 작동이 가능합니다. Python이란 C, C++, Java 등과 같은 프로그래밍 언어입니다. 다른 프로그래밍 언어들 보다 직관적이서 프로그래밍이 쉽고 Windows, Mac OS, Linux 등 모든 운영체제에서 사용이 가능하기 때문에 연구 분야에서 많이 사용하고 있습니다. 따라서, 처음 인공지능 연구를 시작하시는 분들도 위에 언급된 Keras, TensorFlow, PyTorch 등을 시작하기 전에 먼저 Python 부터 공부를 시작하셔야 합니다. 이렇게 정리하고 보니 초심자는 준비해야 할 것이 조금 많긴 하네요. 그러나, 통계 분석을 위해 R이나 Stata 등을 사용했던 경험이 있으시다면 Python을 익히는데 큰 어려움을 겪지 않으실 것 같습니다. 관련 서적이나 인터넷 자료, 동영상 강의 등을 찾아보시면서 약 1주일 정도 시간을 투자하시면 어느 정도는 이해가 가능하시리라 믿습니다. Python프로그래밍이 어느 정도 눈에 익었다면 딥러닝 프레임워크를 선택하셔서 인공지능 혹은 딥러닝 연구를 시작해 볼 수 있습니다.
이제 직접 프로그래밍을 해보려면 위에서 말씀드린 Python과 Keras 등의 프레임워크를 컴퓨터에 설치해야 합니다. 이를 위해서 Anaconda, CUDA, cuDNN 등 각종 패키지/라이브러리를 설치해야 하는데, 사실 이 과정도 녹록치 않습니다만 최근에는 인터넷에 잘 정리된 자료들이 있습니다. 사용하고 계시는 컴퓨터의 운영체제가 Windows, MacOS, Linux에 관계없이 모두 잘 설치가 되고 특히 대부분 무료로 다운로드 받아서 설치가 가능하니 천천히 잘 따라가면서 설치해 보시기를 권합니다.
인공지능은 막노동(?)의 산물이다 – 1. 데이터 전처리
프로그래밍 언어와 딥러닝 프레임워크 그리고 개발환경에 익숙해지기 위해 open source code와 data로 간단한 작업을 해보셨다면, real world data로 진짜 연구를 시작해 보고 싶으실 겁니다. 의료데이터를 활용해서 연구를 하시려면 데이터 심의위원회와 IRB에서 비식별화 적정성 등의 평가를 받고 안전한 데이터 사용을 통한 연구 허가를 미리 받으셔야 하는 것은 아마 아실 것으로 생각합니다. 이제 모든 준비가 완료되어 실전으로 딥러닝 모델을 학습시키고 싶은 마음이 간절하시겠지만, 그 전에 가장 많은 정성을 들여야 하는 때가 데이터 준비 및 전처리입니다. 이 데이터 전처리 과정을 꼼꼼하게 진행하지 않으면 오랜 시간동안 학습시켰던 모델을 어쩔 수 없이 버리고 다시 학습해야 하는 과정을 반복할 수밖에 없습니다. 이런 일들이 심심치 않게, 아니 꽤 자주 (새로운 데이터로 신규 연구를 수행할 때마다 아마도 거의 매번) 발생하니 아무리 꼼꼼하게 살펴보아도 지나침이 없습니다. 전체 연구 시간의 80% 이상이 데이터 전처리 때문에 소요된다는 얘기가 있을 정도이니까요.
X-ray, CT, MRI 등 영상의 경우를 먼저 생각해 보겠습니다. Convolutional Neural Networks (CNN)을 활용한 딥러닝 모델을 주로 많이 학습하게 될 텐데, 일반적으로는 모든 학습데이터를 동일한 크기의 영상으로 resize를 먼저 해야 합니다. (프레임워크에 따라서는 동일한 크기가 아닌 경우 학습이 진행되지 않습니다) 병리 영상과 같이 매우 큰 영상의 경우는 전체 영상을 resize하면 너무 많은 정보를 잃어버릴 수 있기 때문에, 조직이 포함된 여러 개의 작은 패치(patch)들로 쪼갠 후에 resize를 수행합니다. 뿐만 아니라 X-ray와 같은 단일 채널(channel) greyscale 영상의 경우는 중복(duplicate)을 통해 3 채널 영상으로 미리 변환하기도 합니다 (3채널 영상으로 미리 학습한 pretrained model을 활용하기 위해). 영상 전처리의 거의 마지막 단계에서는 영상의 각 픽셀(pixel)값을 원래의 값이 아닌 0과 1사이의 소수점으로 정규화(normalize)를 한 후, 다시 한번 해당 위치의 pixel값들의 평균값들을 빼 주는 mean subtraction 단계를 수행하기도 합니다. 이렇게 전처리를 수행한 경우가 대부분의 경우 조금 더 좋은 성능을 나타내기 때문입니다. 그런데 예를 들어 CT의 경우는 Hounsfield Unit (HU)로 데이터가 구성되어 있고 window level과 window width 조정에 따라 데이터가 달라집니다. 마찬가지로 영상의 contrast 전처리 여부에 따라서 딥러닝 모델의 성능에 엄청난 차이를 내기도 합니다. 또 하나의 문제는 장비마다 영상 특성이 다를 수도 있기 때문에 표준화 방법에 따라 성능에 영향을 미칠 수도 있습니다. 위에서 설명한 내용을 포함해서 개략적으로 의료 영상에 필요한 전처리 기법들을 아래와 같이 나열해 볼 수 있겠습니다.
- Denoising, Registration, Resize, ROI crop/detection, image channel preprocessing, image normalization, mean subtraction, image enhancement (e.g., contrast enhancement), standardization,
위 기법들 외에도 더 있을 수도 있고, 이중에 어떤 기법들을 조합해서 적용해야 할지는 데이터에 따라 너무 천차만별이라 정답이 없습니다. 그러니 이런 저런 조합을 연구자의 직감으로 시도해 보아야 합니다. 이미 엄청난 막노동이 필요하다는 느낌이 올 겁니다. 그러므로, 비교적 초심자는 한정된 computing 자원을 통해 real world data에서 최적의 성능을 내는 모델을 빨리 학습하기가 힘들 수 있습니다. 다른 분야 에서와 마찬가지로, 의료 인공지능 분야에서도 진짜 전문가가 되려면 논문 등의 문헌이나 자료에서는 찾을 수 없는, 수많은 실패로부터 쌓은 연구경험이 필요합니다.
EMR에서 추출할 수 있는 여러 임상 데이터를 엑셀 테이블 자료 형태(정형 데이터)로 만들고, 이를 이용해 질병의 예측 모델 등을 위한 딥러닝 모델을 학습한다면 신경 써야 할 전처리가 더 많을 수 있습니다. 먼저 컴퓨터가 이해할 수 있도록 모든 자료를 숫자로 변환해야 합니다. 특히 명목척도로 구분되어 있는 변수는 여러 개의 변수를 따로 만들어서 분리해 줘야 합니다. 예를 들어 아래 그림처럼 one-hot vector나 multi-hot vector 형태로 변환해 줘야 합니다. Neural Network알고리즘의 경우 모든 입력 변수를 기본적으로 연속형 (continuous) 변수로 인식하기 때문에, 이러한 전처리를 하지 않으면 의도치 않은 결과를 초래할 수 있습니다.
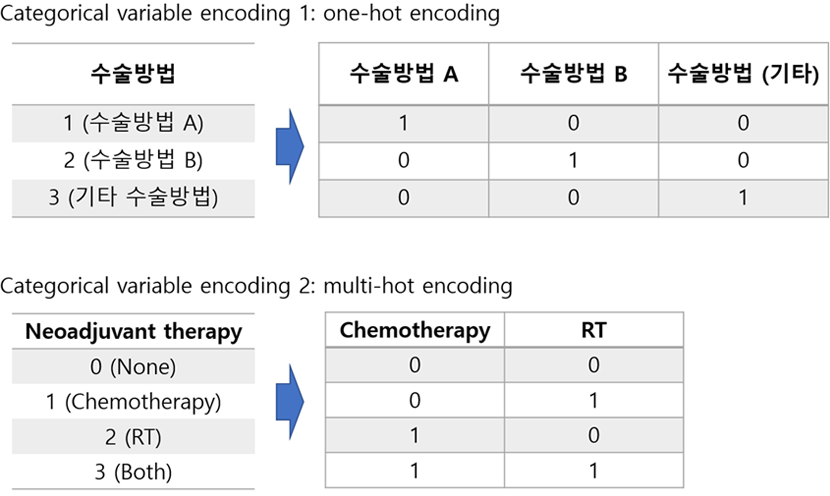
다기관 데이터를 활용한다면 당연히 제일 신경 써야 할 것이 데이터 표준화인데, 각 기관마다 데이터 구조 뿐 아니라 표현방식에 있어서도 차이가 많이 있기도 하고, 그에 따라 결측치가 존재할 수도 있으니 이에 대한 고려도 필수적이라 하겠습니다. 최근에 국제표준을 준용한 의료데이터 표준화에 대한 정부차원에서의 노력이 있고 많은 의료기관들이 이에 참여를 시작하고 있지만, 그 전에는 어쩔 수 없이 한 땀 한 땀 수작업이 필요할 수밖에 없겠습니다.
인공지능은 막노동(?)의 산물이다 – 2. Hyperparameter 최적화
데이터 준비가 완료됐다면 이제 드디어 딥러닝 학습을 시도해 볼 차례입니다. 여러 가지 기계 학습 알고리즘들을 테스트해 보고 싶을 겁니다. 영상의 경우는 CNN 기반의 Googlenet (Inception), Resnet, Densenet 등의 딥러닝 알고리즘들을 첫번째 사용 옵션으로 고려해 볼 수 있습니다. 딥러닝 알고리즘은 각 영역에서 무시무시한 속도로 발전하고 있고, 지금 이 순간에도 새로운 알고리즘에 대한 논문이 전세계적으로 쏟아져 나오고 있습니다. 내가 해결하려는 문제에 가장 적합한 알고리즘 (딥러닝 알고리즘의 경우에는 Neural Network 구조(Architecture)에 해당)을 찾아 나가는 것이 Hyperparameter 최적화 과정 중에 가장 먼저 고려해야할 것입니다. Hyperparameter는 User parameter로 바꿔 부를 수도 있는데, 모델의 학습을 시작하기 전에 사용자(연구자)가 미리 지정해두는 parameter로써 모델 구조, Learning rate, Mini-batch size 등이 있습니다. 이 Hyperparameter 조합을 통해 최적의 성능을 내는 모델을 찾아내는 방식을 Hyperparameter 최적화 혹은 Hyperparameter tuning이라고 합니다. 예를 들어 아래의 경우를 생각해 보겠습니다.
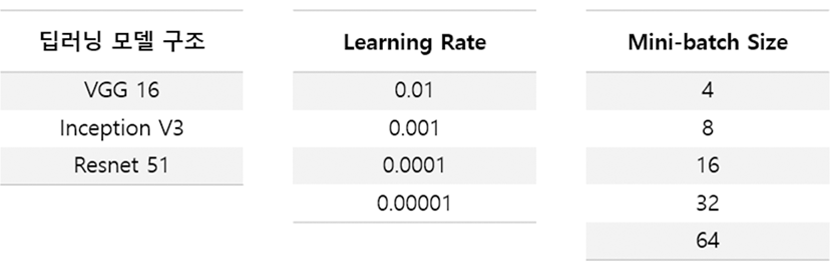
위의 경우처럼 모델 구조 3가지, Learning rate 4가지, Mini-batch size 5가지의 선택지가 있다고 가정할 때, Hyperparameter의 조합은 345=60. 즉, 60가지 조합이 있고, 이 60가지 조합을 각각 적용하여 학습한 후 가장 최적의 성능을 보이는 모델을 찾는 것이 Hyperparameter tuning 과정입니다. 실제 연구에서는 훨씬 더 많은 종류의 user parameter들이 있고 선택지의 개수도 훨씬 더 많을 수 있으므로 실제 조합의 개수는 기하급수적으로 늘어나게 되며, 따라서 이 부분에서도 엄청나게 많은 막노동과 Computing 자원이 필요하다는 것을 느끼실 수 있습니다. 이러한 상황 때문에 인공지능 연구 분야에서도 貧益貧 富益富의 양극화 현상이 발생하고 있습니다. 많은 연구 인력과 Computing 자원을 보유하고 있는 기업이나 연구기관이 지속적으로 뛰어난 결과를 발표하고 있고, 이를 기반으로 다시 재투자가 일어나서 우수인력과 자원을 지속적으로 흡수하는 선순환 구조가 만들어지고 있습니다. 인공지능 분야에서 우수인력을 구하기가 점점 더 힘들어지는 이유 중 하나라고 볼 수 있겠습니다.
위에 예에서 60가지 Hyperparameter 조합을 모두 시도해서 최적의 모델을 찾는 방식을 Grid Search라고 부릅니다. Computing 자원이 풍부하다면 시도할 수 있겠지만, 현실적으로는 연구자의 직관과 경험에 의해 그 탐색 범위를 좁혀 나가는 Manual Search방식을 선택하기도 합니다. 뿐만 아니라 전체 Hyperparameter중에 무작위로 일부만 선택해서 찾는 Random Search 방식도 적용되기도 하는데, 그 성능이 Grid Search 방식과 크게 차이 나지 않는다는 보고도 많이 있습니다. 최근에는 Hyperparameter를 스마트하게 빨리 찾아내는 방식에 대한 연구 분야가 부각되고 있습니다. Bayesian optimization, Gradient-based optimization, 진화 알고리즘을 활용한 Evolutionary optimization 등이 시도되고 있습니다. 특히 딥러닝 알고리즘에서 가장 기본적인 Hyperparameter라고 볼 수 있는 ‘내 문제를 가장 잘 해결할 수 있는 Neural Network모델 구조’를 data-driven 방식으로 알고리즘 스스로가 학습하여 찾아 나가도록 하는 Neural Architecture Search (NAS)가 주요 인공지능 학회에서도 많은 관심을 갖고 연구되고 있는 분야라고 할 수 있습니다.

초심자가 Hyperparameter tuning을 처음부터 잘 수행해 내기는 사실 쉽지 않습니다. 물론 여기에도 ‘초심자의 행운’ 이 작동할 수도 있겠지만, 사실상 백사장에서 바늘 찾기와 다르지 않은 경우가 많기도 하고, 특히나 탐색 시작 지점이나 범위를 잘 못 정하면 아예 학습이 진행되지 않는 경우가 있어서 시작부터 좌절을 맛볼 수 있습니다. 그래서, 최근에는 게으른(?) 연구자들을 위해 Automated Machine Learning 즉 AutoML이라는 프로세스, 플랫폼 혹은 서비스가 개발되고 있습니다. 즉, 기계학습 모델이나 구조를 선정하는 것부터 Hyperparameter tuning까지 자동으로 선정되도록 하는 프로세스가 소개되고 있는데, 이에 대해서는 다음 편에 소개해 드리겠습니다.